Tags with MySQL fulltext
While setting up the promised performance test in my last post, I did some tests with the MySQL fulltext features and it seems that they are built for tagging systems. Take a look at the queries (if it is not clear for you what is done here, please read my previous post).
I took the MySQLicious schema and added ALTER TABLE delicious ADD FULLTEXT (tags).
The full schema:
`CREATE TABLE `delicious` ( `id` int(11) NOT NULL auto_increment, `url` text, `description` text, `extended` text, `tags` text, `date` datetime default NULL, `hash` varchar(255) default NULL, PRIMARY KEY (`id`), KEY `date` (`date`), FULLTEXT KEY `tags` (`tags`) ) ENGINE=MyISAM`
Queries
Intersection
Intersections can be done using boolean fulltext search (since MySQL 4.01):
Query for semweb+search:
SELECT * FROM delicious WHERE MATCH (tags) AGAINST ('+semweb +search' IN BOOLEAN MODE)
Now this was easy. And, you guess it, Minus is very similar:
Minus
Query for search+webservice-search:
SELECT * FROM delicious WHERE MATCH (tags) AGAINST ('+search +webservice -search' IN BOOLEAN MODE)
Brackets
Even brackets are possible:
Query for (del.icio.us|delicious)+(webservice|project):
SELECT * FROM delicious WHERE MATCH (tags) AGAINST ('+(del.icio.us delicious) +(webservice project)' IN BOOLEAN MODE)
Union
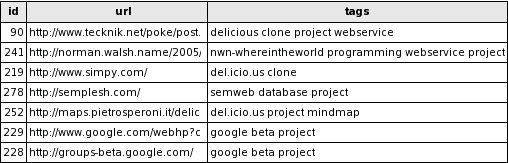
For union you could use the already mentioned boolean mode, but if you want to have the results ordered so that the bookmark with the most “hits” is the first entry of the result try this sort of query:
SELECT * FROM delicious WHERE MATCH (tags) AGAINST ('delicious clone project webservice')
If you take a look at the screenshot of the first 7 results of the query run on my DB, you can see that the first hit has got all four tags we searched for, the second has got two and the rest has got just one of them. Like this you can do a “find similar entries” very easily.
Downsides and problems
There are two points where difficulties can accur: When MySQL builds its index out of the tags and when searching for specific tags. I stumbled on three problems:
Stopcharacters
If you insert tags with characters like “-“ (as in “my-comment”), then MySQL will make two index entries: One for “my” and one for “comment”. Vice versa if you search for “my-comment” you’ll find bookmarks with tag “my” and those with tag “comment”. It seems that this problem can be eliminated by setting the character set of the column “tags” to latin1_bin but this feature is not available before MySQL 4.1.
But nontheless this shouldn’t be a showstopper. You could replace “-“ with a string, say “minus“. This is ugly but should do it..
Stopwords
When searching for or indexing tags like “against” or “brief” (full list of stopwords), these tags will not be regarded.
Since MySQL 4.0.10 you can customize your stopwordlist.
Minimum length of a tag
Per default, the minimal length of a word indexed by MySQL fulltext is 4 characters. You should therefor edit my.cnf in order to set the minimal tag length to 1.
Performance
This solution scales ok. I did tests with tables from 1000 to 1 million bookmarks.
The time for inserting a bookmark is the same for small as for big tables. The time for an intersection query was 0.001 (finding 0.7 urls averaged) in the 1000-table and 0.1 seconds in the 1 million-table(finding 70 bookmarks averaged). There are some discussions about if MySQLs fulltext search is fast or not (have a look at the user comments). Quick performance tests showed that it is about 10 times as fast as the LIKE-queries mentioned in my previous post. But I guess it is not fast enough for webservices like del.icio.us, I guess this services have to run more than 10 queries a second and then this solution is too slow..
Update: I tested the performance of this setup.
Comments